对数据驱动的地球系统科学深度学习和过程的理解
发布日期 :2026-01-05来源:Reichstein,M.,Camps-Valls,G.,Stevens,B.,Jung,M.,Denzler,J.,&Carvalhais,N.(2019).Deep learning and process under standing for data-driven Earth system science.Nature,566(7743),195.
贺洁颖(山西省气科所)、唐伟(中国气象局发展研究中心)摘译
田晓阳 审校
摘要:机器学习方法正在越来越多地用于从不断增加的地理空间数据中提取分布规律和线索,但当系统行为受空间或时间要素主导时,目前的方法可能不是最佳的。这些(空间和时间)背景场应该被用作深度学习(一种能够自动提取时空特征的方法)的一部分,以获得对地球系统科学问题的进一步理解,提高季节预测能力和多时空尺度模拟,而不是仅仅改进传统的机器学习方法。下一步方向将是混合建模方法,将物理过程模型与数据驱动机器学习的多功能性耦合起来。
人类总是努力预测和认识这个世界,更好的预测能力在很多背景下(如天气、疾病或金融市场)都具有竞争优势。地球科学中的一个成功案例是天气预报,但我们也只能准确预测日尺度而不是月尺度的天气演变。近年来海量的地球系统数据已经出现,存储量已经远远超过几十PB,并且传输速率迅速提高,每天超过数百TB。地球系统数据具备典型的“大数据”的“4V”特征:体积、速度、多样性和准确性(图1)。一个关键的挑战是从这些大数据中实时提取可解释的信息和知识并在学科之间进行整合。
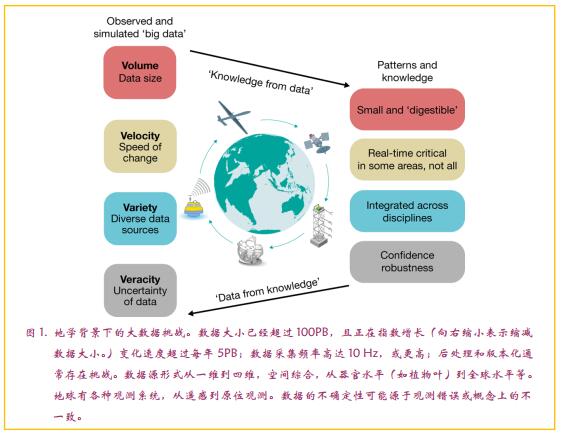
但我们收集和创建数据的能力远远超过我们能够理智地同化它的能力,更不用说理解它了。过去几十年中,预测能力并没有随着数据量一并提高。前所未有的数据源,增强的计算能力以及统计建模和机器学习的最新进展相结合,为我们从数据中拓展对地球系统的认识提供了令人振奋的新机会。尤其是,机器学习和人工智能领域有许多工具可供使用,但它们需要进一步地开发和适应地球科学分析。
先进地学机器学习
现在,机器学习成功地应用在了几个地学领域对大气、陆表和海洋处理方案的研究和业务上,并且在过去十年中与数据可用性共同发展。大约30年前,由于同时出现了高分辨率卫星数据和神经网络方法的首次复兴,机器学习的早期里程碑事件是对土地覆盖类型和云的种类进行分类。当适用于相关方法的数据变得可用时,大多数主要的机器学习方法(例如,核方法或“随机森林”)被应用于地球科学和遥感问题。因此,机器学习已成为地球科学的分类、变化和异常检测问题的通用方法。在过去的几年里,地球科学已经开始利用深度学习来更好地提取数据中的时空结构,而用传统机器学习方法提取这些时空结构特征通常很困难。
尽管机器学习在地球科学取得了成功,更广泛的应用和影响受到重要注意事项和局限性的限制。最佳实践和专家干预应避免一些陷阱,如原始外推的风险、抽样或其他数据偏差、忽视混杂因素、将统计关联解释为因果关系或多重假设检验中的基本缺陷(‘P值捕捞’)。从根本上讲,目前应用的机器学习方法存在固有的局限性。在这个领域,深度学习技术有望取得突破。
经典机器学习方法得益于特定范围,手动添加的特征,以解决时间或空间依赖性(例如,从日常时间序列中得出的累积降水量),但很少彻底挖掘时空依赖性。例如,在海洋-大气或陆地-大气二氧化碳通量预测中,将瞬时、局部环境条件(如辐射、温度和湿度)映射到瞬时通量。实际上,在某个时间点和空间的过程几乎总是受到系统状态的额外影响,这种状态通常没有被很好地观测到,因此不能作为预测因子。但是,先前的时间步长和相邻的网格单元包含有关系统状态的隐藏信息(例如,长时间没有降雨,加上持续晴天,意味着干旱)。空间和时间要素高度相关的一个例子是火灾发生的预测与诸如燃烧区域和痕量气体排放的特征预测。火灾的发生和蔓延不仅取决于瞬时气候驱动因素和起火源(如人类、闪电或两者兼而有之),还取决于状态变量,如可用燃料的状态和数量。火势蔓延,于是燃烧区域不仅取决于每个像素的局部条件,还取决于燃料的空间布局和连通性、水分、地形特性,当然还取决于风速和风向。同样,将某一大气状况归类为飓风或温带风暴需要了解空间背景知识,例如由像素构成的风暴几何结构、值以及其拓扑结构。例如,检测流出层和可见“风眼”对于检测飓风和评估它们的强度是重要的,而这不能仅通过局部的单像素值来确定。
几十年来,遥感图像分类一直采用类似的方法。手动设计的特征既可以被视为一种优势(解释性驱动因素的控制变量),也可以是一种劣势(繁琐的,临时的过程,可能不是最优的),但当然,对机器学习的手动设计存在很多担忧,因为它使用的是受限制的、受主观选择影响的方法而不是广泛通用方法。然而,深度学习的新发展不再限制我们采用这种方法。
地球系统科学中深度学习的机遇
在计算机视觉、语音识别和控制系统以及物理、化学和生物学等相关科学领域,深度学习在空间背景的有序序列和数据模拟方面取得了显著的成功。对地球科学问题的应用尚处于起步阶段,但在关键问题(分类、异常检测、回归、空间或时间相关状态预测)上,有一些很有前景的例子(图2)。最近的两项研究表明深度学习应用于极端天气问题,例如飓风检测——已经提到过传统机器学习存在问题。这些研究成功地应用深度学习架构,客观地提取空间特征,以定义和分类数值天气预测模式输出中的极端情况(如风暴、大气河流)。这种方法可以快速检测此类事件并预测模拟,而无需使用主观的人工注释或依赖于风速或其他变量的预定义任意阈值的方法。特别地,这种方法使用事件的空间形状中的信息,例如典型的飓风涡旋。同样,对于城市区域的分类,从遥感数据中自动提取多尺度特征大大提高了分类精度(几乎总是大于95%)。
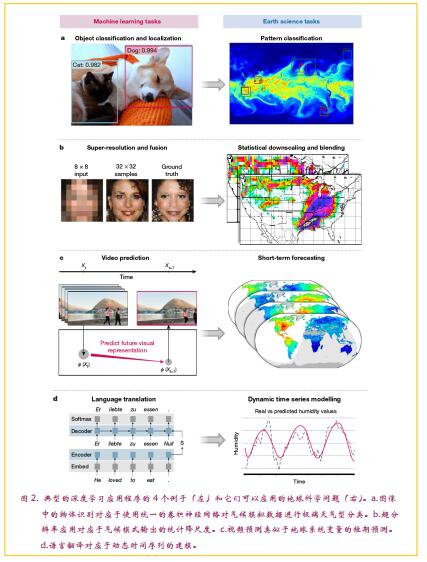
简而言之,与传统深度学习应用相关的数据类型与地球科学数据之间的相似性为深度学习与地球科学的整合提供了令人信服的论据(图2)。图像类似于包含与照片中的颜色三元组(RGB值)类似的特定变量的二维数据字段,,而视频可以视为图像序列,从而视作随时间演变的二维字段。类似的,自然语言和语音信号与地球系统变量动态时间序列一样也具有相同的多分辨率特征。再者,分类、回归、异常检测和动态建模都是计算机视觉和地球科学中的典型问题。
地球系统科学中深度学习的挑战
上面概述的传统深度学习应用和地球科学应用之间有惊人的相似之处,但仍存在许多差异。例如,传统计算机视觉应用处理具有三个通道(红色,绿色,蓝色)的照片,高光谱卫星图像却延伸到远远超出可见范围的数百个光谱通道,这通常会引起与自然图像的统计不同的统计特性。这包括变量的空间依赖性和相互依赖性,违反了独立同分布数据的重要假设。此外,由于不同的传感器显示出不同的成像几何形状、空间和时间分辨率、物理意义、内容和统计数据,因此集成多传感器数据并非易事。(多传感器)卫星观测序列还具有各种噪声源、不确定性水平、数据缺失和(通常是系统的)间隙(由于云或雪的存在,采集、存储和传输中的失真等)。
此外,光谱、空间和时间维度带来了计算上的挑战。数据量不断快速增长,全球范围内每天需要处理数PB级的数据。目前,最大的气象机构通常每天必须处理TB级的高精度(32位,64位)数据。此外,虽然典型的计算机视觉应用已能处理512×512像素的图像尺寸,但是中等分辨率(约1km)的全球场的大小约为40,000×20,000像素,即多三个数量级。
最后,与Image Net(人类标记图像的数据库,例如“猫”或“狗”等标签)不同,地球科学中并不总有大型、带标记的地球科学数据集,不仅仅是因为所涉及的数据集的大小,也由于标注数据集方面存在概念上的困难;例如,确定描绘猫的图像比确定反映干旱的数据集要容易得多,因为干旱取决于强度和程度,并且随收集和分析数据所用的方法会有变化,同时没有足够的标记样本用于训练机器学习系统。除了训练集有限这一挑战外,地球科学问题往往缺乏约束,导致可能被认为是高质量的模型,这些模型在训练甚至测试数据集中表现良好,但对于有效域之外的情况和数据(外推问题),偏差很大,对于复杂的物理地球系统模型也是如此。总的来说,在地球科学中成功应用深度学习方法存在五大挑战和途径。
(1)可解释性
提高预测准确度很重要,但还不够。当然,可解释性和理解性是至关重要的,包括结果可视化以供人类分析。可解释性已被认为是深度神经网络的潜在弱点,实现它是当前深度学习的焦点。该领域仍远未实现自解释模型,也远未从观测数据中发现因果关系。然而,我们应该注意到,鉴于现代地球系统模型的复杂性,它们在实践中往往不容易追溯到它们的假设,这也限制了它们的可解释性。
(2)物理一致性
深度学习模型可以非常好的拟合观测,但是由于诸如外推或观测偏差,预测可能存在物理上不一致或不可信。通过教学模式整合领域知识和实现物理一致性来控制地球系统的物理规则,可以在观测的基础上提供非常强的理论约束。
(3)数据的复杂和不确定性
为了处理复杂的统计数据、多个输出、不同的噪声源和高维空间,需要采用深度学习方法。新的网络拓扑不仅需要利用局部邻域(甚至在不同尺度上),而且还非常需要远程关系(例如遥相关),但变量之间的确切因果关系尚不清楚,需要进一步挖掘。建模的不确定性无疑是一个重要方面,需要集成贝叶斯/概率论推理的概念,直接解决此类不确定性。
(4)缺少标记样本
在只有少量的标记样本时,需要用深度学习方法来利用相关的未标记观测数据中的丰富信息。这些方法包括无监督密度建模、特征提取、半监督学习和域自适应。
(5)计算需求
当前地球科学问题的高计算成本是一个巨大的技术挑战,如何解决这一问题的一个很好的例子是谷歌的地球引擎,它可以解决从森林砍伐到湖泊监测等实际问题,并有望在未来跟进深度学习应用。
通过应对这些挑战,深度学习可以在地球科学中产生比在传统计算机视觉领域更大的影响,因为在计算机视觉中,手工特征提取源于对世界的清晰理解(表面的存在,物体之间的边界等等),从世界到图像的映射,以及关于二维图像上世界点(表面点)的(视觉)外观的假设。成功处理的假设包括朗伯表面(即,强度不依赖于表面和光源之间的角度)的假设,这个经典的假设即随着时间的推移,观测三维点的强度是恒定的。此外,在大多数情况下,世界上的变化(物体的运动)被模拟为刚性变换,或者由物理假设产生的、仅在局部有效的非刚性变换(例如在肿瘤切除前后的大脑结构的配准中)。甚至计算机视觉中的复杂问题也通过反映公认常识假设和期望的手工特征提取得以解决。在地球科学和气候科学中,这种全球、一般性的知识仍然不完整,我们在研究中寻求的正是这种知识(因此,它不能是一个假设)。从遥感图像的分割到某些变量的回归分析,所有问题都具有某些已知有效或至少是良好近似的假设。然而,对技术流程的理解越少,建模中实现高质量手工特征提取的可能性就越低。因此,深度学习方法,特别是因为它们从数据中找到了很好的表示方法,为解决地球科学和气候研究问题提供了机遇。
最有前景的近期应用包括临近预报(即,气象学中预测未来两个小时内的天气)和预测应用、基于空间和时间背景信息的异常检测和分类。长期前景包括数据驱动的季节性预测、跨多个时间尺度的空间长距离相关性建模、空间背景下的空间动态建模(例如,火灾),以及检测人们可能没有想到的变量之间的遥相关和联系。
我们推断,深度学习很快将成为地球科学中对时空结构进行分类和预测的主要方法。更具挑战性的是,除了最佳预测之外,还要获得理解;实现从数据中最大限度地学习的模型,同时不抛开物理和生物学知识。实现这一目标的一个有希望但还很少探索的方法是将机器学习与物理建模相结合,我们接下来将讨论这一点。
与物理模拟集成
从历史上看,物理模拟和机器学习通常被视为两个不同的领域,具有截然不同的科学范式(理论驱动与数据驱动)。然而,这些方法实际上是互补的,物理方法原则上可以直接解释,并提供超出观测条件的外推潜力,而数据驱动方法在适应数据方面具有高度的灵活性,并且易于发现意外模式(惊喜)。这两种方法之间的协同作用一直受到关注,在基准测试和紧急约束概念中有所体现。
机器学习和地球科学中观测和模拟能力的进步为以多种方式更集中地整合仿真和数据科学方法提供了机遇。从系统建模的角度来看,存在五个方面的潜在协同作用(见图3,其中编号的圆圈对应于以下编号的列表)。
(1)改进参数化
见图3(圈1),物理模型需要参数,但其中许多参数不易从基本原则中推导出来。机器学习可以学习参数化,以最佳方式描述地面真实情况(可以通过基本原则观测或者由复杂的高分辨率模型生成的)。例如,我们可以从适当的统计协变量集合中学习这些参数化,而不是将地球系统模型中的植被参数分配给植物功能类型(在大多数全球陆地表面模型中是一种常见的特别决策),从而使它们更具动态性、相互依赖性和关联性。在水文学中已经采用了一种典型方法,从几千个流域中学习到了环境变量(如降水量和表面坡度)到流域参数(如平均、最小和最大流量)的映射,并已应用于全球水文模型中。全球大气模型的另一个例子是从数据或高分辨率模型(高分辨率模型的运行成本太高,因此需要进行粗尺度参数化)中学习对流降水的有效粗尺度物理参数(例如,对流过程中云层降水的水的比例)。这些学习的参数化可以更好的表示热带对流。
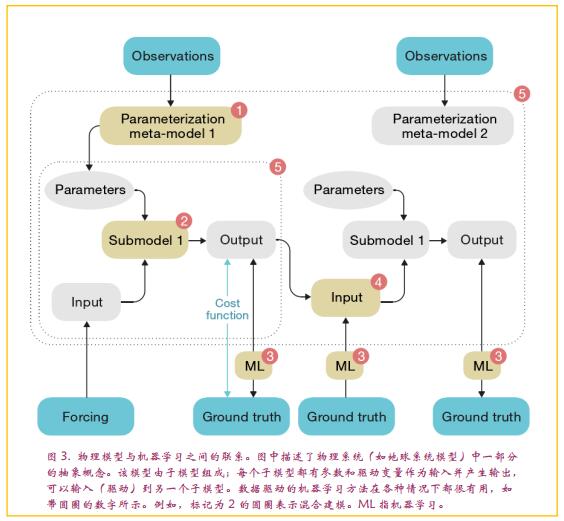
(2)用机器学习模型代替“物理”子模型
见图3(圈2),如果子模型的公式是半经验性质的,而函数形式没有什么理论基础(如生物过程),那么如果有足够的观测数据,则可以用机器学习模型来代替该子模型。这带来了混合模型,它结合了物理建模(理论基础、可解释的单元)和机器学习(数据适应性)的优势。例如,我们可以将已建立的植被水分运输的物理(微分)扩散方程与机器学习耦合起来,用于弥补对水传输电导的生物学调控的不了解。这导致了一个更“物理”的模型,它遵循公认的质量守恒和能量守恒定律,但它的规则(生物学)是从数据中学习到的并且是灵活的。这些原理最近被用来有效地模拟海水在海洋中的运动,特别是预测海面温度。在这里,运动场是通过深度神经网络学习的,然后通过物理模拟运动场隐含的运动来更新热含量和温度。此外,一些大气科学家已经开始试验相关的方法来规避大气对流物理参数化中长期存在的偏差。
如果要在保持可解释性的同时估算物理模型和机器学习参数,则问题可能变得更加复杂,尤其是当用机器学习方法替换多个子模型时。在化学领域,这种方法已被用于校准练习,并描述未知动力学速率的变化,同时在生化反应器模拟中保持质量平衡,虽然不太复杂,但与水文和生物地球化学模型有许多相似之处。
(3)模型-观测不匹配的分析
见图3(圈3),假设没有观测偏差,物理模型与观测的偏差可以认为是认知不够导致模型误差。机器学习有助于识别、可视化和理解模型误差的模式,这也使我们可以相应地校正模型输出。例如,机器学习可以自动从数据中提取模式,并识别未在物理模型中明确表示的模式。这种方法有助于改进物理模型和理论。在实践中,它还可以用于校正动态变量的模型偏差,或者与繁琐和临时的手动设计方法相比,它可以帮助改进降尺度到更精细的空间尺度。
(4)约束子模型
见图3(圈4),可以使用机器学习算法的输出来驱动子模型,而不是在离线模拟中使用另一个(可能有偏差的)子模型。这有助于理清耦合子模块中造成模型误差的那个子模块是哪一个。因此,这简化并减少了模型参数校准或观测系统状态变量同化中的偏差和不确定性。
(5)替代模型或仿真
见图3(圈5),由于计算效率和易处理,物理模型的全部(或特定部分)的仿真是有用的。机器学习仿真器一旦经过训练,就可以比原始物理模型更快地实现数量级的仿真,而不会牺牲太多的精度。这允许快速灵敏度分析,模型参数校准以及估算置信区间的推导。例如,机器学习仿真器用于替代计算上昂贵的,基于物理的辐射、植被和大气之间相互作用(这对模型中地表遥感的解释和同化至关重要)的辐射传输模型。仿真器也用于状态演变的动态建模,例如,在气候模型以及最近的在植被动态模型中进行的探索。此外,鉴于物理模型的复杂性,仿真挑战是非常好的探索机器学习和深度学习方法在训练条件范围之外进行外推的潜力的测试平台。
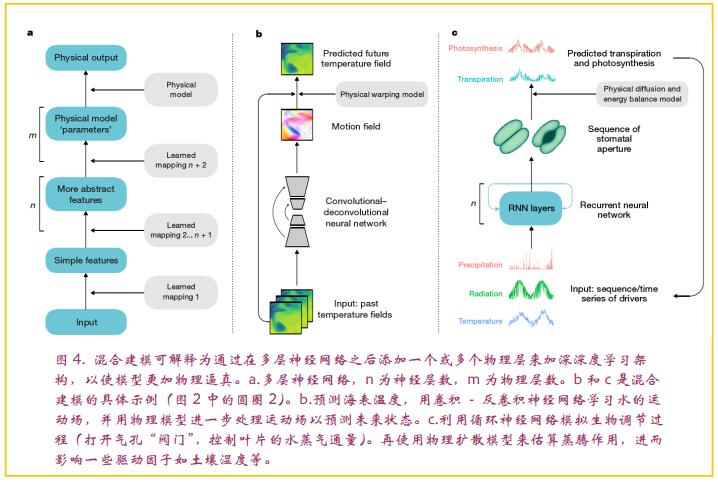
广义来说,图3中的一些概念已被采用。例如,与模型基准、降尺度统计及模型输出统计有关的应用。在这里,我们认为采用深度学习方法将极大地改善时空背景信息的使用,以修改模型输出。仿真(5)已经在工程和地球科学的几个分支中被广泛采用,主要是为了有效模拟,但易处理性问题尚未得到深入的研究。其他方法,例如混合模拟似乎研究得更少。从概念上讲,上面讨论的混合方法可以解释为深化神经网络(图4)以使其更加物理逼真,其中物理模型位于神经网络层之上(参见图4b,c中的示例)。它与上面讨论的反向方法形成对比,后者产生物理模型输出,然后使用额外的机器学习方法层进行校正。我们认为,物理建模和机器学习相结合的两种途径是值得探索的。
图3给出的系统建模视角是为了将机器学习集成到系统模型中。还有一种视角,系统知识可以集成到机器学习框架中。这可能包括网络架构的设计、用于优化的成本函数中的物理约束,或者针对欠采样域的训练数据集扩展(即,基于物理的数据增强)。例如,通常所谓的成本函数(如普通最小二乘法)用来惩罚模型-数据不匹配,但进行修正后可以用来避免对湖泊温度模拟的物理不可信预测。物理和机器学习模型的集成不仅可以提高性能和通用性,而且可能更重要的是,它结合了机器学习模型的一致性和可靠性。作为副产品,混合具有有趣的正则化效应,即物理学抛弃了不可信的模型。因此,物理感知机器学习模型应该能更好地克服过度拟合,尤其是在低至中等的样本数据集中。这个观点还涉及实现可解释的方向和可解释的机器学习模型(可解释的人工智能),以及将逻辑规则与深层神经网络相结合。
两个方法论方法领域的最新进展有助于以稳健的方式促进机器学习和物理模型的融合:概率编程和可微分编程。概率编程允许以正式但灵活的方式计算各种不确定性因素。对数据和模型不确定性进行适当的计算以及通过先验和约束对知识进行整合对于优化组合数据驱动和理论驱动的范式(包括逻辑规则)至关重要,正如统计关系学习中所做的那样。此外,错误传播在概念上是无缝的,有助于为模型输出提供有根据的不确定性边界。目前还基本没有这种能力,但对于科学目的,特别是管理或政策决策至关重要。由于自动化求导,可微分编程允许有效率的优化。这有助于使大型、非线性和复杂的反演问题更易于计算,此外,还允许明确的灵敏性度评估,从而有助于解释。
推进科学发展
毫无疑问,现代机器学习方法极大地提高了分类和预测技能。仅此一点就很有价值。然而,除了统计预测之外,问题在于数据驱动方法如何能够提高基本的科学理解,因为复杂统计模型的结果通常很难解释。一个基本答案是,观测几乎总是科学进步的基础。例如,哥白尼的发现是通过精确观测行星轨迹来推断和测验其运行规律的。
现在,虽然探索、生成假设和测试的一般周期保持不变,但现代数据驱动的科学和机器学习可以在观测数据中提取任意复杂的模态,以挑战复杂的理论和地球系统模型。例如,基于机器学习的空间显式全球数据驱动的光合作用评估表明,气候模型高估了热带雨林的光合作用。这种不匹配使得科学家们提出假设,能够更好地描述植被冠层中的辐射传递,从而在其他地区进行更好的光合作用评估,并与叶层观测结果更加一致。与此相关,数据驱动的碳循环评估使我们得以对植被模型进行校准,并有助于解释高纬度地区CO2浓度季节性振幅增大的难题,(根据这些结果)这是高纬度地区植被更茂盛造成的。
除了数据驱动的理论和模型构建之外,这些提取的模态越来越多地被用作探索地球系统模型中改进参数化的方法,并且模型仿真器越来越多地被用作为模型校准的基础[88]。这样,理论与观测、假设生成与理论驱动假设检验之间的科学相互作用将继续存在。由于通过强大的机器学习技术,从数据得出的假设和检验的复杂性,以及假设生成的速度都呈数量级增长,我们可以期待复杂地球系统科学在定性和定量方面取得前所未有的进展。
结论
地球科学需要处理大量且快速增加的数据,以预测、模拟和理解复杂地球系统的形式,提供更准确、不确定较少的、物理上一致的推论。机器学习,特别是深度学习提供了有前途的工具,可以为地球系统各组成部分构建新的数据驱动模型,从而建立我们对地球的理解。地球系统特有的挑战将进一步促进深度学习方法的发展,对此我们有如下4项主要建议。
(1)识别数据的特殊性
多源、多尺度、高维度、复杂的时空关系,包括变量之间的重要的和时间滞后的长距离关系(遥相关),需要进行充分的建模。深度学习可以很好地解决这些数据挑战,需要开发网络架构和算法,以产生解决不同尺度的空间和时间背景的方法(见图4)。
(2)推论的合理性和可解释性
模型不仅应该是准确的,而且应该是可信的,应结合地球系统的物理原理。如果模型变得更加含义清晰和可解释,将有助于在地球科学中广泛采用机器学习:它们的参数和特征排序至少应具有一定的物理解释,并且该模型应该可以通过一组规则、描述符和关系来简化或解释。
(3)不确定度估算
模型应该定义他们的置信度和可信度。贝叶斯/概率推理应该集成到模型中,因为这种推理允许显式表示和传播不确定度。此外,识别和处理外推法是优先事项。
(4)对复杂物理模型的测试
机器学习的空间和时间预测能力至少应与物理模型中观测到的模式一致。因此,我们建议根据地球系统的物理模型得出的合成数据测试机器学习方法的性能。例如,图4b、c中,应用于实际数据的模型应该在复杂物理模型模拟的广泛动态范围内进行测试。这在有限的训练数据和评估外推问题的条件下特别相关。
总的来说,我们建议未来的模型应该整合基于物理过程的和机器学习的方法。数据驱动的机器学习方法在地球科学研究中不会取代物理建模,而是对物理建模强有力的补充和丰富。具体而言,我们设想了物理和数据驱动模型之间的各种协同作用,其最终目标是混合建模方法:这些方法应遵循物理定律,具有概念化,因而可解释的结构,同时在理论薄弱的地方能完全适应数据。重要的是,机器学习研究将受益于源自自然科学的合理的基于物理的关系。其中,两个目前几乎没有取得进展的地球系统主要挑战——大气对流参数化问题和生态系统对气候和地理因素相互作用的时空依赖性描述问题,可以使用本文讨论的混合方法来解决。